
NVIDIA Blackwell Ultra Revolutionizes AI Inference, Cutting Costs and Boosting Performance
The landscape of artificial intelligence is undergoing a rapid transformation, driven by the need for faster, more efficient, and cost-effective inference. NVIDIA is at the forefront of this revolution, with its Blackwell platform already gaining widespread adoption among leading providers like Baseten, DeepInfra, Fireworks AI, and Together AI to reduce the cost per token by up to 10x. Now, the next-generation NVIDIA Blackwell Ultra is poised to accelerate this momentum, particularly for the burgeoning field of agentic AI.
The demand for AI agents and coding assistants is exploding, with software-programming-related AI queries surging from 11% to approximately 50% in the past year, according to OpenRouter’s State of Inference report. These applications demand exceptionally low latency for real-time responsiveness and the ability to process vast amounts of contextual information – essential for reasoning across complex codebases. But can current infrastructure truly meet these escalating demands?
Blackwell Ultra: A Leap in Performance and Efficiency
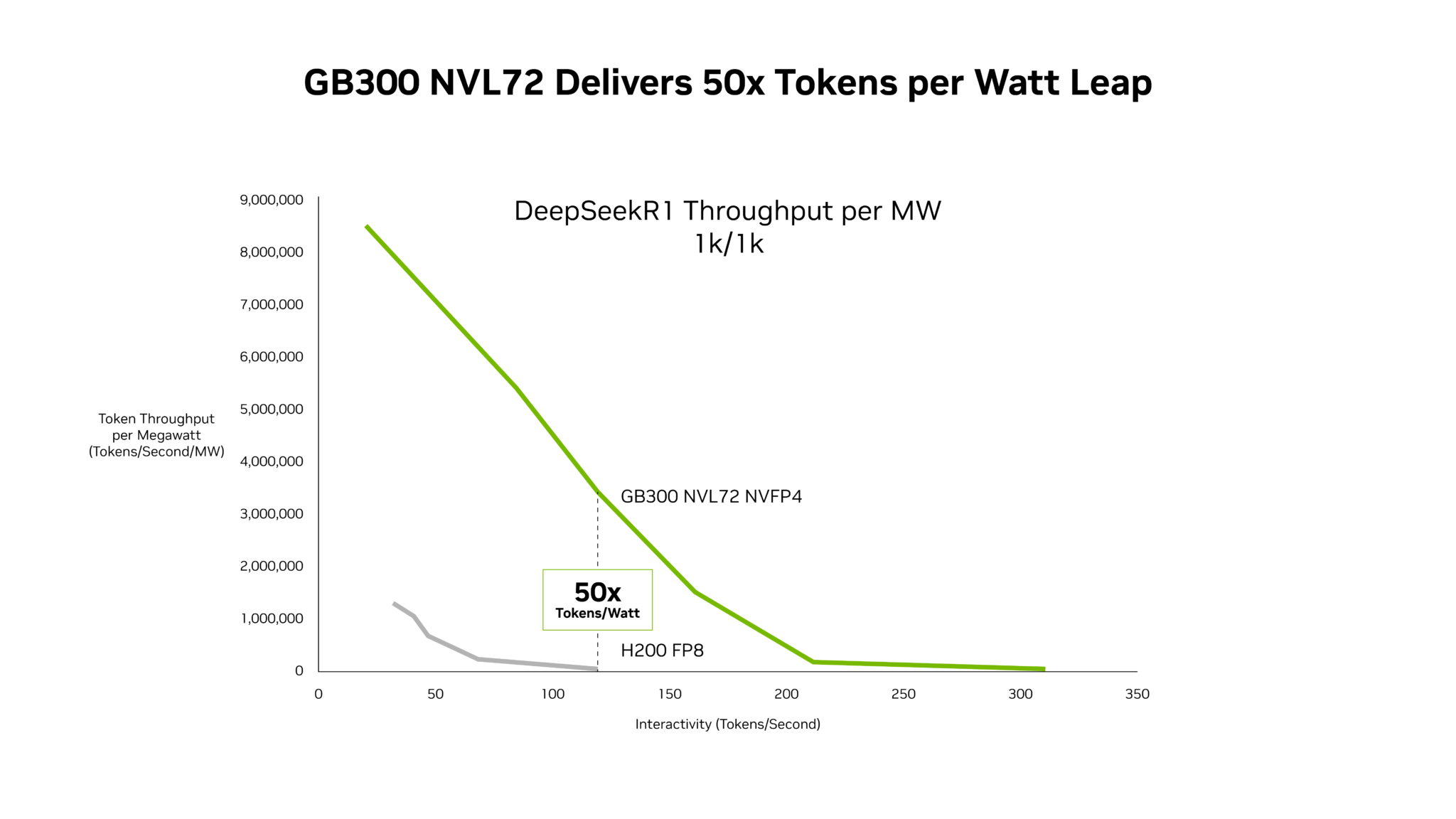
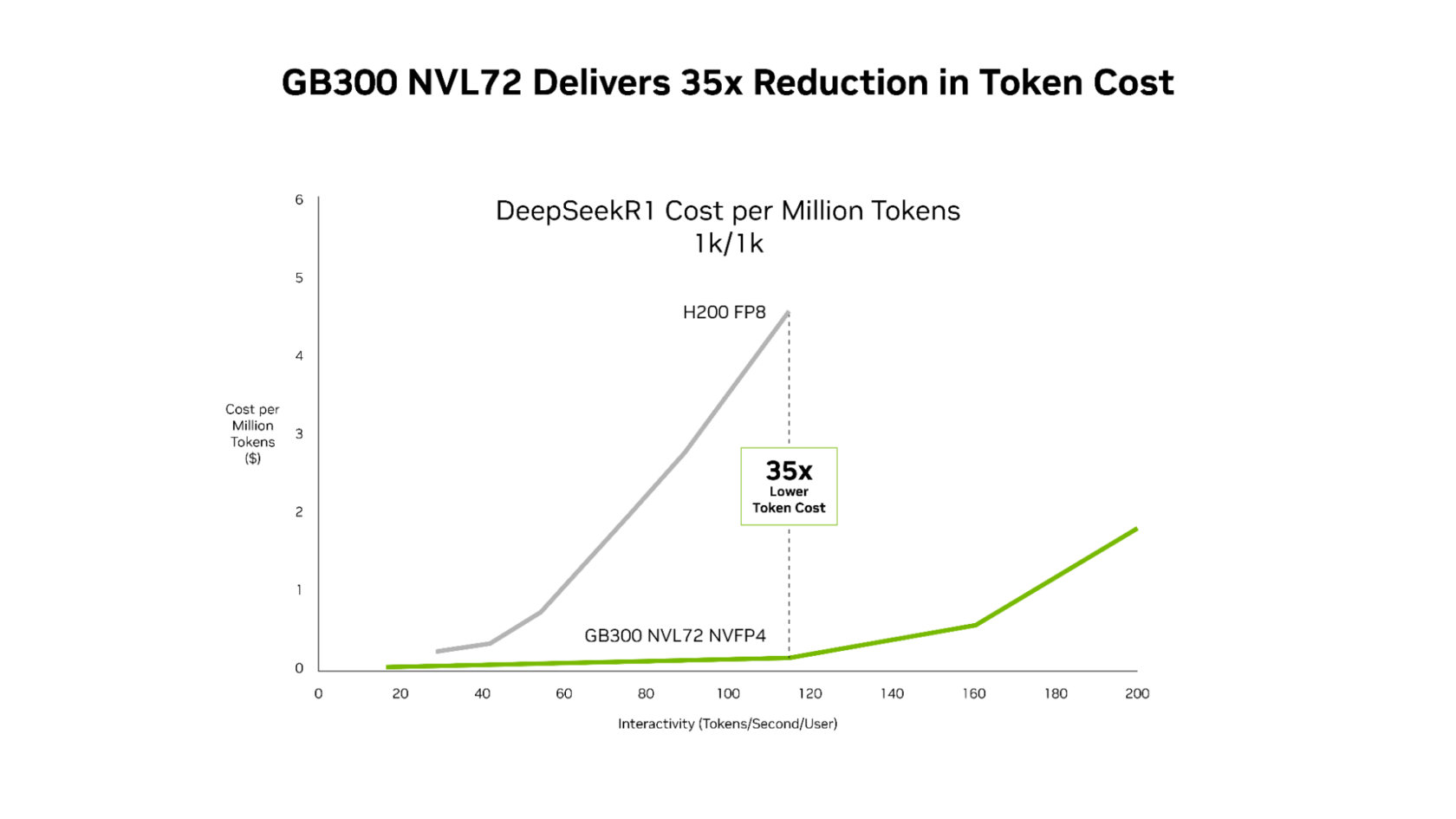
Recent performance data from SemiAnalysis InferenceX demonstrates the significant advancements achieved through the combination of NVIDIA’s software optimizations and the Blackwell Ultra platform. The NVIDIA GB300 NVL72 systems now deliver up to 50 times higher throughput per megawatt, translating to a remarkable 35 times reduction in cost per token compared to the previous generation, NVIDIA Hopper platform.
NVIDIA’s success stems from a holistic approach to innovation, encompassing advancements in chip design, system architecture, and software. This “extreme codesign” philosophy accelerates performance across a wide range of AI workloads, from agentic coding to interactive coding assistants, while simultaneously driving down operational costs.
GB300 NVL72: Unprecedented Low-Latency Performance
Analysis from Signal65 reveals that the NVIDIA GB200 NVL72, leveraging this extreme codesign, delivers over 10 times more tokens per watt, resulting in a tenfold reduction in cost per token compared to Hopper. These gains are not static; they continue to expand as the software stack matures.
Continuous optimizations from teams focused on NVIDIA TensorRT-LLM, NVIDIA Dynamo, Mooncake, and SGLang are significantly boosting Blackwell NVL72 throughput for mixture-of-experts (MoE) inference across all latency targets. Notably, improvements to the NVIDIA TensorRT-LLM library have yielded up to a 5x performance increase on GB200 for low-latency workloads in just the past four months.
- Higher-performance GPU kernels are meticulously optimized for efficiency and low latency, maximizing the computational power of Blackwell.
- NVIDIA NVLink Symmetric Memory facilitates direct GPU-to-GPU memory access, enabling more efficient communication and data transfer.
- Programmatic dependent launch minimizes idle time by proactively launching the setup phase of the next kernel while the previous one is still completing.
Building upon these software advancements, the GB300 NVL72 – powered by the Blackwell Ultra GPU – pushes the boundaries of throughput-per-megawatt, achieving a 50x improvement over the Hopper platform. This translates into substantial economic benefits, with NVIDIA GB300 offering lower costs across the entire latency spectrum, with the most significant reductions occurring at low latency – the sweet spot for agentic applications, achieving up to 35x lower cost per million tokens compared to Hopper.
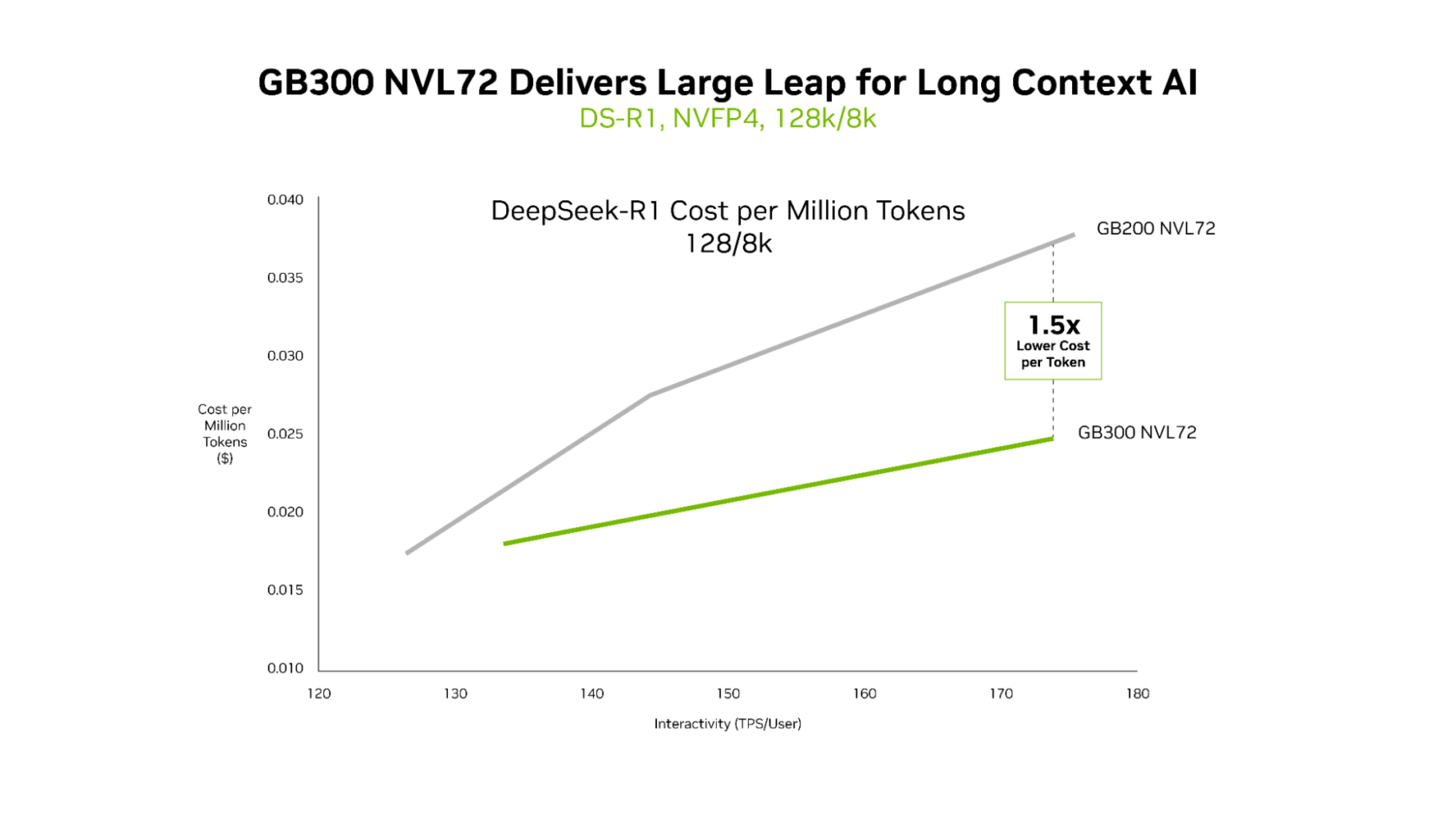
Long-Context Workloads: A New Level of Efficiency
While both GB200 NVL72 and GB300 NVL72 excel at delivering ultralow latency, the advantages of GB300 NVL72 become particularly pronounced in long-context scenarios. For workloads involving 128,000-token inputs and 8,000-token outputs – common in AI coding assistants reasoning across extensive codebases – GB300 NVL72 delivers up to 1.5x lower cost per token compared to GB200 NVL72.
As agents process more code, their understanding improves, but computational demands increase exponentially. Blackwell Ultra, with its 1.5x higher NVFP4 compute performance and 2x faster attention processing, empowers agents to efficiently analyze entire codebases.
Infrastructure Adoption and Future Outlook
Leading cloud providers and AI innovators are already deploying NVIDIA GB200 NVL72 at scale and are rapidly adopting GB300 NVL72 for production workloads. Microsoft, CoreWeave, and OCI are integrating GB300 NVL72 into their infrastructure to support low-latency and long-context applications like agentic coding and coding assistants. By reducing token costs, GB300 NVL72 unlocks a new generation of applications capable of reasoning across massive codebases in real-time.
“As inference moves to the center of AI production, long-context performance and token efficiency become critical,” says Chen Goldberg, senior vice president of engineering at CoreWeave. “Grace Blackwell NVL72 addresses that challenge directly, and CoreWeave’s AI cloud, including CKS and SUNK, is designed to translate GB300 systems’ gains, building on the success of GB200, into predictable performance and cost efficiency. The result is better token economics and more usable inference for customers running workloads at scale.”
Looking ahead, the NVIDIA Rubin platform – integrating six new chips into a unified AI supercomputer – promises another substantial leap in performance. For MoE inference, Rubin is projected to deliver up to 10x higher throughput per megawatt compared to Blackwell, further reducing the cost per million tokens to one-tenth. Moreover, Rubin will enable the training of large MoE models using just one-fourth the number of GPUs required by Blackwell.
What impact will these advancements have on the future of AI-powered software development? And how will these cost reductions democratize access to advanced AI capabilities?
Frequently Asked Questions About NVIDIA Blackwell Ultra
-
What is the primary benefit of the NVIDIA Blackwell Ultra platform?
The primary benefit is a significant reduction in cost per token for AI inference, coupled with substantial performance improvements, particularly for agentic AI and long-context workloads.
-
How does the GB300 NVL72 system compare to the NVIDIA Hopper platform?
The GB300 NVL72 system delivers up to 50x higher throughput per megawatt and a 35x lower cost per token compared to the NVIDIA Hopper platform.
-
What role does software optimization play in Blackwell’s performance?
Software optimizations, including those from NVIDIA TensorRT-LLM, NVIDIA Dynamo, Mooncake, and SGLang, are crucial for maximizing throughput and efficiency.
-
What are the advantages of GB300 NVL72 for long-context AI workloads?
GB300 NVL72 delivers up to 1.5x lower cost per token compared to GB200 NVL72 for workloads with large input sizes, such as AI coding assistants reasoning across extensive codebases.
-
What is the NVIDIA Rubin platform, and how does it build on Blackwell’s advancements?
The NVIDIA Rubin platform is the next generation of AI supercomputing, promising up to 10x higher throughput per megawatt for MoE inference and enabling the training of larger models with fewer GPUs.
Share this article with your network to spark a conversation about the future of AI inference and the transformative potential of NVIDIA’s Blackwell Ultra platform. Join the discussion in the comments below!
Disclaimer: This article provides information for general knowledge and informational purposes only, and does not constitute professional advice.
Discover more from Archyworldys
Subscribe to get the latest posts sent to your email.