
Most Medical AI Research Isn’t Using Real Patient Data, Study Finds
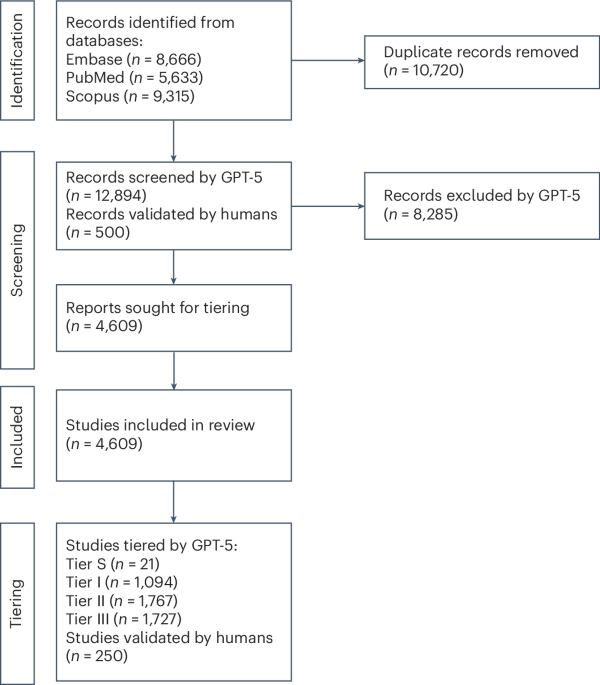
A newly released analysis reveals a significant gap between the rapid development of large language models (LLMs) in healthcare and their application to genuine clinical challenges. The study, powered by an LLM-driven systematic review of over 1,000 research papers, indicates that the vast majority of current investigations do not utilize real-world patient data. This finding raises questions about the immediate translational potential of these AI advancements.
The Rise of LLMs in Medicine: Promise and Peril
Large language models, the same technology powering popular chatbots, are increasingly being explored for a wide range of medical applications. These include tasks like diagnostic assistance, drug discovery, personalized treatment planning, and streamlining administrative processes. The potential benefits are enormous – faster diagnoses, more effective therapies, and reduced healthcare costs. However, the effectiveness of these models hinges on their ability to learn from comprehensive and representative datasets.
Why the Data Disconnect?
Researchers suggest several factors contribute to the limited use of real-world clinical data. Access to such data is often restricted by privacy regulations like HIPAA, requiring extensive de-identification and data use agreements. Furthermore, the complexity and messiness of real-world data – incomplete records, inconsistent formatting, and inherent biases – pose significant challenges for LLM training. Many studies currently rely on synthetic data or publicly available datasets, which may not accurately reflect the nuances of clinical practice.
What impact will this have on the future of AI in healthcare? Will the current trajectory lead to models that perform well in controlled settings but falter when confronted with the complexities of actual patient care? These are critical questions that the medical community must address.
The reliance on non-clinical data also introduces the risk of perpetuating existing health disparities. If the data used to train these models doesn’t adequately represent diverse populations, the resulting AI systems could exhibit biased performance, leading to unequal access to quality care. External resources like the Office of the National Coordinator for Health Information Technology provide further insight into the ethical considerations of AI in healthcare.
Bridging the Gap: Towards Clinically Relevant AI
Overcoming the data barrier requires a multi-faceted approach. This includes developing robust data de-identification techniques, establishing secure data-sharing platforms, and fostering collaboration between researchers, clinicians, and data privacy experts. Furthermore, investment in federated learning – a technique that allows models to be trained on decentralized datasets without directly sharing the data – could offer a promising pathway forward. The Healthcare Information and Management Systems Society (HIMSS) is actively working to address these challenges and promote responsible AI adoption.
Frequently Asked Questions About LLMs and Clinical Data
-
What are large language models (LLMs) and how are they used in healthcare?
LLMs are advanced AI systems capable of understanding and generating human language. In healthcare, they’re being explored for tasks like medical summarization, diagnosis support, and patient communication.
-
Why is real-world clinical data important for training medical LLMs?
Real-world data reflects the complexities and nuances of actual patient care, ensuring that LLMs are accurate and reliable in clinical settings.
-
What are the challenges of accessing and using real-world clinical data?
Privacy regulations, data complexity, and the need for robust data governance pose significant hurdles to accessing and utilizing real-world clinical data.
-
How can we ensure that medical LLMs are fair and unbiased?
Using diverse and representative datasets, and actively monitoring for bias, are crucial steps in developing fair and unbiased medical LLMs.
-
What is federated learning and how can it help?
Federated learning allows LLMs to be trained on decentralized datasets without directly sharing the data, addressing privacy concerns and enabling broader data access.
-
What is the potential impact of this lack of real-world data on patient care?
Without sufficient real-world data, LLMs may not perform as expected in clinical settings, potentially leading to inaccurate diagnoses or ineffective treatments.
As AI continues to reshape the healthcare landscape, ensuring that these powerful tools are grounded in real-world evidence will be paramount. The future of medicine may well depend on it.
What steps do you think are most critical to facilitate responsible data sharing in healthcare? And how can we best mitigate the risks of bias in medical AI systems?
Share this article with your network to spark a conversation about the future of AI in medicine!
Disclaimer: This article provides general information and should not be considered medical advice. Always consult with a qualified healthcare professional for any health concerns or before making any decisions related to your health or treatment.
Discover more from Archyworldys
Subscribe to get the latest posts sent to your email.