
New AI Framework, MedHELM, Revolutionizes Medical Large Language Model Evaluation
A significant leap forward in artificial intelligence for healthcare has been announced with the development of MedHELM, a groundbreaking evaluation framework designed to rigorously test the capabilities of large language models (LLMs) in real-world clinical settings. This new system promises to accelerate the responsible integration of AI into medicine, ensuring accuracy and reliability before deployment.
Understanding the Need for Robust Medical AI Evaluation
The rapid advancement of LLMs has opened exciting possibilities for transforming healthcare, from assisting with diagnosis to streamlining administrative tasks. However, the inherent complexities of medical knowledge and the potential for serious consequences from errors necessitate exceptionally thorough evaluation. Existing benchmarks often fall short, lacking the breadth and nuance required to assess an LLM’s true clinical competence.
Introducing MedHELM: A Comprehensive Framework
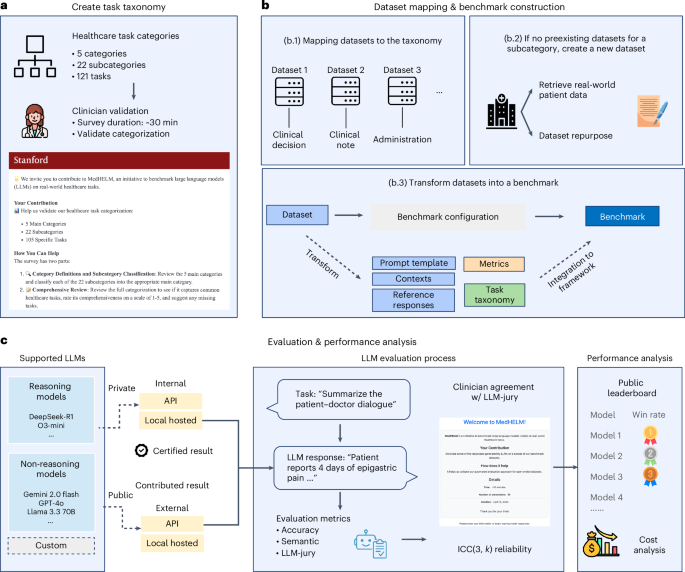
MedHELM addresses these shortcomings by providing an extensible framework complete with a novel taxonomy for categorizing medical tasks. This taxonomy allows for a more granular and targeted assessment of LLM performance. Crucially, MedHELM incorporates a benchmark comprised of numerous datasets spanning these diverse categories, offering a comprehensive testbed for evaluating AI models.
The framework isn’t simply a static evaluation tool; its extensible nature allows researchers to continually add new tasks and datasets, ensuring it remains relevant as the field of medical AI evolves. This adaptability is vital for keeping pace with the ever-expanding capabilities of LLMs and the changing needs of the healthcare industry.
How MedHELM Works: Classifying and Benchmarking
MedHELM’s core innovation lies in its structured approach to evaluating medical LLMs. The new taxonomy classifies tasks based on the type of medical reasoning required – for example, diagnosis, treatment planning, or patient education. Each task is then assessed using a variety of datasets, providing a multifaceted view of the LLM’s strengths and weaknesses.
This detailed analysis allows developers to identify areas where their models need improvement, leading to more reliable and effective AI-powered healthcare solutions. But what does this mean for patients? Could more accurate AI lead to earlier diagnoses and better treatment outcomes? And how will this impact the role of medical professionals in the years to come?
The development of MedHELM represents a critical step towards building trust in medical AI. By providing a standardized and rigorous evaluation process, it paves the way for the safe and responsible deployment of these powerful technologies. Further information about the framework can be found at Nature Medicine.
To learn more about the broader landscape of AI in healthcare, explore resources from the Healthcare Information and Management Systems Society (HIMSS).
Frequently Asked Questions About MedHELM and Medical AI Evaluation
-
What is the primary purpose of the MedHELM framework?
MedHELM’s main goal is to provide a standardized and comprehensive method for evaluating large language models on real-world clinical tasks, ensuring their reliability and safety before deployment in healthcare settings.
-
How does MedHELM differ from existing medical AI benchmarks?
MedHELM distinguishes itself through its extensible framework and a new taxonomy for classifying medical tasks, allowing for a more granular and targeted assessment of LLM performance compared to previous benchmarks.
-
What types of medical tasks can be evaluated using MedHELM?
MedHELM can evaluate a wide range of tasks, including diagnosis, treatment planning, medical question answering, and patient education, thanks to its diverse benchmark datasets.
-
Is MedHELM an open-source project?
Details regarding the open-source availability of MedHELM can be found in the original research publication on Nature Medicine.
-
How will MedHELM impact the future of AI in healthcare?
MedHELM is expected to accelerate the responsible development and deployment of AI in healthcare by providing a reliable and standardized evaluation process, fostering trust and innovation.
-
What role does the taxonomy play in MedHELM’s evaluation process?
The taxonomy allows for a more focused and detailed assessment of LLM capabilities by categorizing medical tasks based on the specific type of reasoning required.
The development of MedHELM marks a pivotal moment in the integration of AI into healthcare. As these technologies continue to evolve, robust evaluation frameworks like MedHELM will be essential for ensuring patient safety and maximizing the benefits of AI-powered medicine.
Disclaimer: This article provides general information about medical AI and should not be considered medical advice. Always consult with a qualified healthcare professional for any health concerns or before making any decisions related to your health or treatment.
Share this article with your network to spark a conversation about the future of AI in healthcare! What ethical considerations should guide the development and deployment of these powerful tools?
Discover more from Archyworldys
Subscribe to get the latest posts sent to your email.